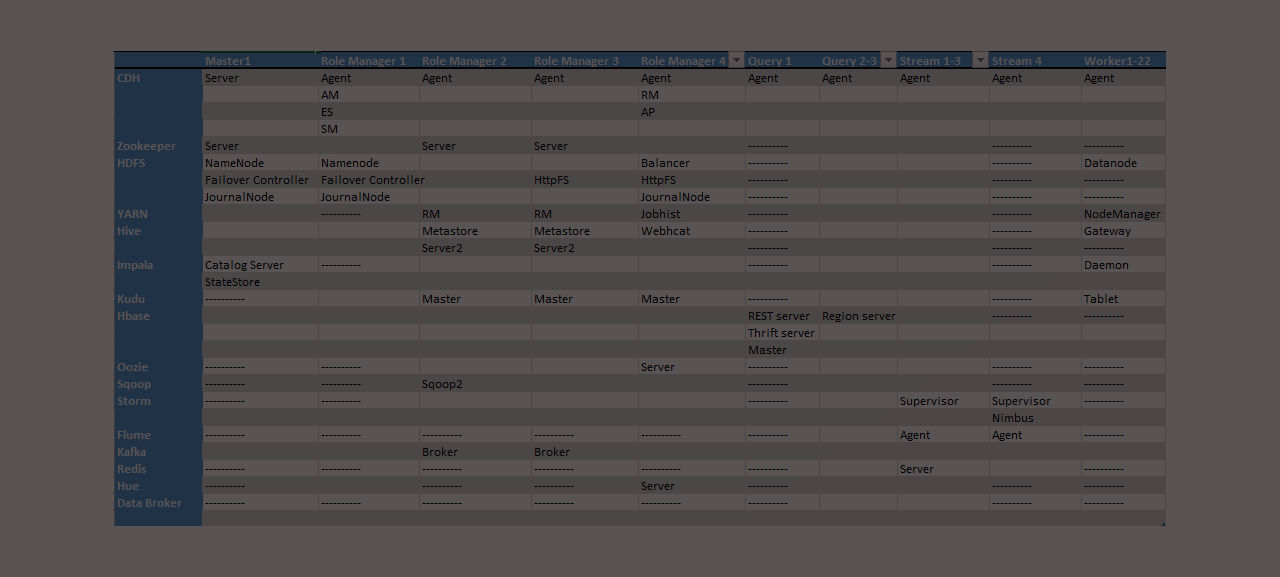
Planning and Communicating Your Cluster Design
When creating a new Amazon Web Services (AWS) hadoop cluster it is overwhelming for most people to put together a configuration plan or topology. Below is a Hadoop reference architecture template I’ve built that can be filled in that addresses the key aspects of planning, building, configuring, and communicating your hadoop cluster on AWS.
I’ve done this many times and as part of my focus on tools and templates thought I’d add a template you can use as a basic guideline for planning your Cloudera big data cluster. The template includes configurations for:
- instance basics
- instance list
- storage
- operating system
- CDH version
- the cluster topology
- metastore detail for hive, YARN, hue, impala, sqoop, oozie, and Cloudera Manager
- high-availability
- resource management
- and additional detail for custom service descriptors (CSD) for Storm and Redis
No Warranty Expressed or Implied
It’s not meant to be exhaustive as there are many items not covered (AWS security groups, network optimization, dockerization, continuous integration, monitors, etc.) but it is an example of a real-world cluster in AWS (details of instance and AZ changed for security).

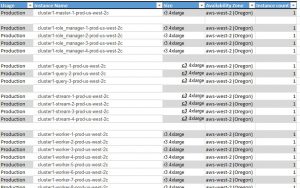
Cloudera hadoop reference architecture configuration template for Amazon Web Services (AWS)
Please feel free to let me know how it works for you and if you have any improvements for it.