
Open Source Virtual Data Lake
Before data virtualization was well-known I was presented with the scenario of a large company that had purchased several other companies and needed to fuse their data. I had already presumed that I would be introducing the Hadoop ecosystem into the portfolio because that was some large part of why they had hired me. Rather than take the approach that has become common now and build a data lake I proposed we use data virtualization along with a custom lightweight layer that performed the major functions of a Multidimensional Online Analytical Processing (MOLAP) engine to allow us to provide immediate business benefit by using their data in-place while providing an abstraction that allowed us to evolve the systems that held the data. Some of the key requirements of this platform was that it must be easily changed, provide query abilities as good as or better than the underlying data stores, and scale linearly. I recommended an architecture that is still unique within our global domain, the concept of a virtual data lake.
Virtual Online Analytical Processing (VOLAP) design
The product we built in 2014 and continue to evolve is unique in the marketplace with the exception of perhaps Denodo. The key difference is that it uses entirely free and open source technologies that can be swapped for others as needed. Currently we have a small java app, Jboss Teiid (swappable for Apache Calcite), and the many data technologies the company uses–(many built based on my reference architecture template) HBase, MySQL, Oracle, Impala, Hive, MongoDB, Cassandra, SalesForce, and external REST APIs.
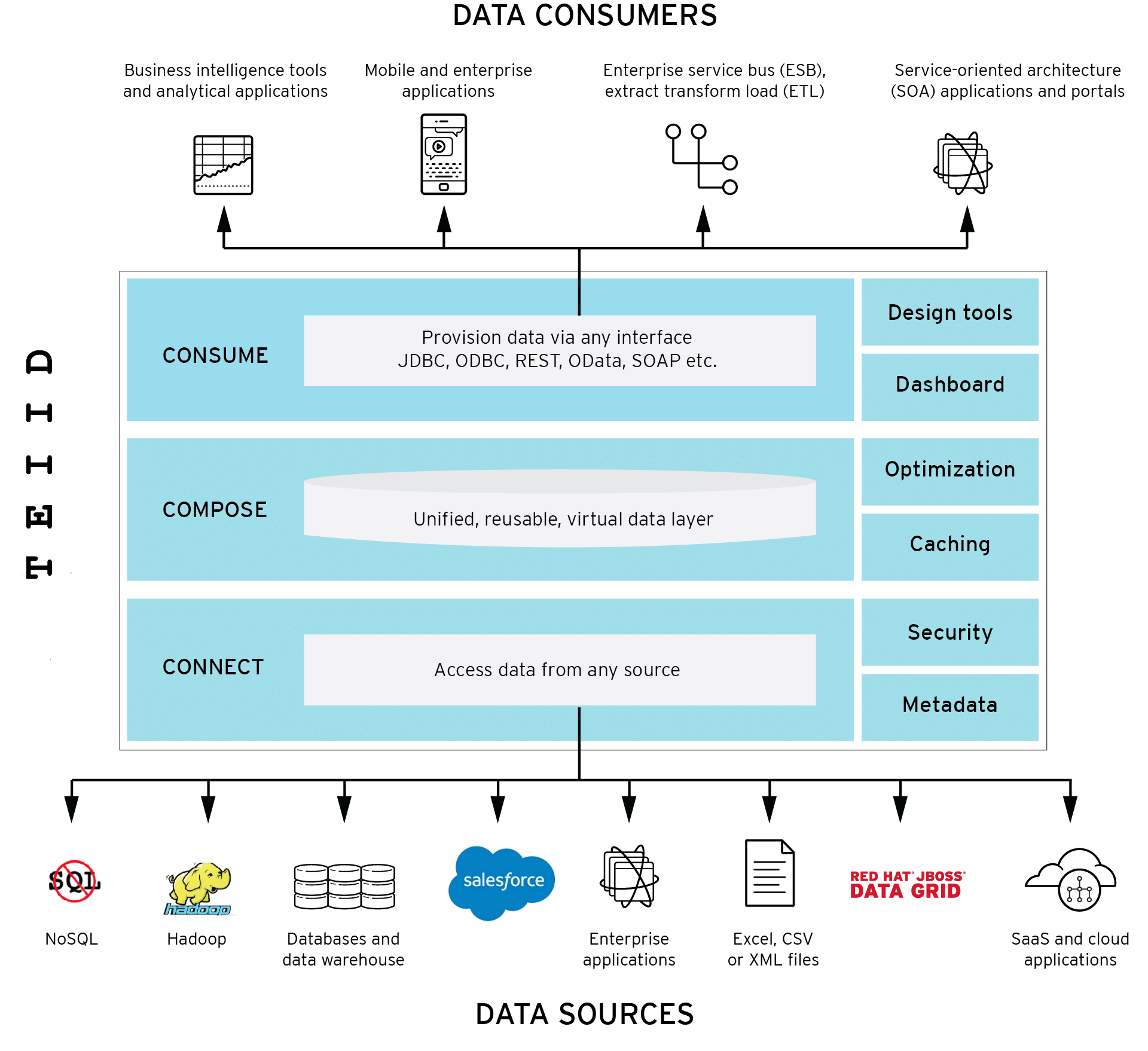
We also designed our our approach to operate as a virtual OLAP (VOLAP) system–an approach that doesn’t currently exist–that adds cost-based routing to make the query run as fast as possible by selecting the fastest data source automatically and executing all possible operations at the data source. The large tech company now leverages this platform as their enterprise data layer–a virtual data lake that performs as a virtualized hybrid OLAP “database”–VOLAP.
The basic premise
REST APIs are arguably the most universal of data interchange methods and for this reason we elected a REST api as our interface for any application that needed data. We support jdbc and odbc as well but discourage their use because we can provide better service through REST (a swagger UI for exploration, traffic smoothing of queries, circuit breakers, security injection, complex in-flight transformations, etc).
I hold that a business expert (mathematical analyst, account manager, HR manager) need not to know the location, context, or formulas to have basic utility of data. They need simple access to data and they add the expertise over that data to provide business value. To that end data virtualization provides a universal adapter and the java application adds a universal language and the business knowledge to the data at query time automatically in a way that is easily governed.
How it works — the request sequence
With more in-depth explanation below, here is how a request for data proceeds in its simplest form:
java app-
REST API->request parser->logical field replacement->data source selection->query writer->
data virtualization-
Query splits into multiples if going to multiple data stores->data store queried->rows buffered and if necessary, aggregated->data streamed back
Injection points exist in our java application that you may consider for such options as plugging in other ways of data sources selection other than cost-based (like semantic, quality of service, or other algorithmic approach), circuit breakers (fail if sql injection attempted, some business rule not passed), and traffic smoothing algorithms such as token bucket for DDOS protection.
Applied example
Assume a web application or spreadsheet wants to determine which customer had the most sales this month in Canada. The application sends a simplified form of the request to a URL that looks very much like a web page using a simplified SQL language:
http://myserver?query=SELECT customer, sales where sale_date between 01/01/2019 and 02/03/2019
- receive the request
This request goes to the java application - extract the logical fields we’ll need to return–customer, sales, and sale_date. These are LOGICAL fields and may or may not correspond to the name of the columns in any of the underlying data storage.
- get the formulas for each field. Assume in your underlying data sources you have identified and mapped a series of sources that contain these fields. In this case assume in the data virtualization layer we have set that customer is an attribute column that is just the column “customer_name”, sales is a metric column that corresponds to the formula “sum(amount_spent – tax_collected)” and sale_date is called “date_of_transaction”.
- use the metadata from the data virtualization layer to identify all data sources with all of these columns–customer_name, amount_spent, tax_collected, and sale_date. There are four because it requires for columns to get the required data. Use the cost-based (or other plug-in) rule to identify which will be quickest. Lowest cardinality of the underlying fact table is usually a good first guess at the lowest cost (fastest) data source.
- write a query to be sent to the virtualization layer that will retrieve these data: select customer_name as customer, sum(amount_spent – tax_collected) as sales from myvirtualtable where date_of_transaction between ’01/01/2019′ and ’02/03/2019′
- send query to virtualization layer, which splits the query into several queries if there are multiple data sources involved (data federation).
- underlying data store is queried and rows sent back to data virtualization layer. If the underlying data provider can’t perform some part of the query natively (called a pushdown operation), such as summing values, the values are returned to the virtualization layer and performed there.
- data are streamed back from the virtualization layer to the java application where it is sent back to the caller
Next, architecture and code.