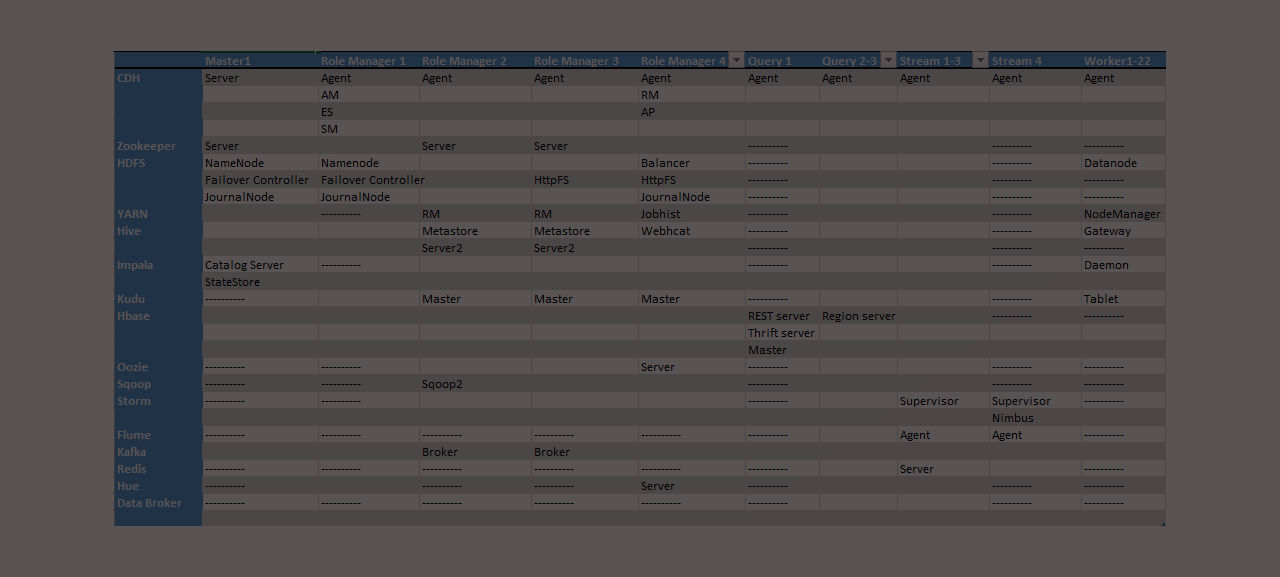
Planning and Communicating Your Cluster Design When creating a new Amazon Web Services (AWS) hadoop cluster it is overwhelming for most people to put together a configuration plan or topology. Below is a Hadoop reference architecture template I’ve built that can be filled in that addresses the key aspects of planning, building, configuring, and communicating… Continue reading Fillable Hadoop reference architecture template for AWS clusters
Tag: AWS
Double your effective IO on AWS EBS-backed volumes

NOTE: This content is for archive purposes only. With generation 4+ EBS volumes big data IO performance no longer requires volume prewarming. Fresh Elastic Block Storage volumes have first-write overhead At my employer I architect Big Data hybrid cloud platforms for global audience that have to be FAST. In our cluster provisioning I find we frequently… Continue reading Double your effective IO on AWS EBS-backed volumes