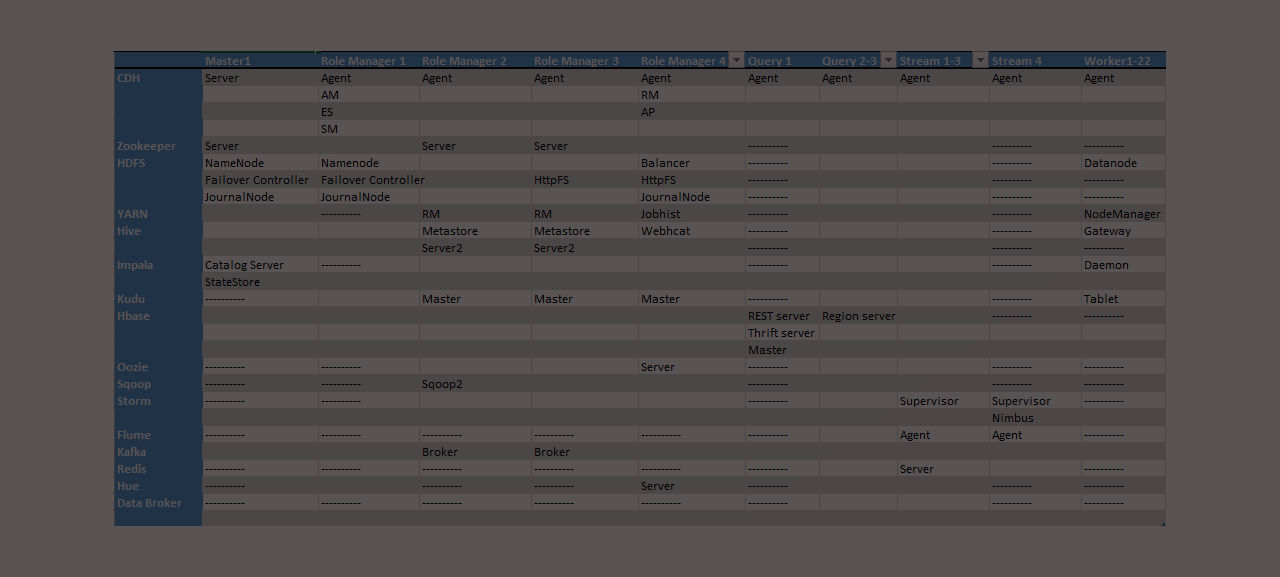
Planning and Communicating Your Cluster Design When creating a new Amazon Web Services (AWS) hadoop cluster it is overwhelming for most people to put together a configuration plan or topology. Below is a Hadoop reference architecture template I’ve built that can be filled in that addresses the key aspects of planning, building, configuring, and communicating… Continue reading Fillable Hadoop reference architecture template for AWS clusters
Tag: big data architecture
NIST Big Data Working Group
The US National Institute of Standards and Technology (NIST) kicked off their Big Data Working Group on June 19th 2013. The sessions have now been broken down into subgroups for Definitions, Taxonomies, Reference Architecture, and Technology Roadmap. The charter for the working group: NIST is leading the development of a Big Data Technology Roadmap. This… Continue reading NIST Big Data Working Group