
Virtual Data Lake — big data at rest

Open Source Virtual Data Lake Before data virtualization was well-known I was presented with the scenario of a large company that had purchased several other companies and needed to fuse their data. I had already presumed that I would be introducing the Hadoop ecosystem into the portfolio because that was some large part of why… Continue reading Virtual Data Lake — big data at rest
Fillable Hadoop reference architecture template for AWS clusters
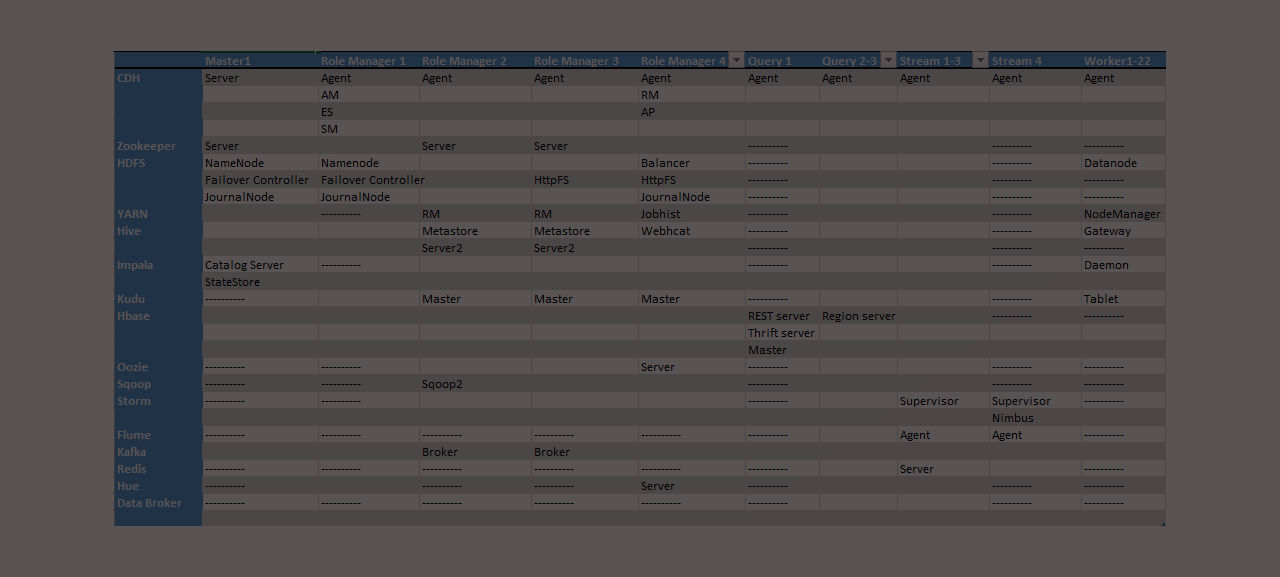
Planning and Communicating Your Cluster Design When creating a new Amazon Web Services (AWS) hadoop cluster it is overwhelming for most people to put together a configuration plan or topology. Below is a Hadoop reference architecture template I’ve built that can be filled in that addresses the key aspects of planning, building, configuring, and communicating… Continue reading Fillable Hadoop reference architecture template for AWS clusters